Introduction to Causal Inference
Correlation is not Causation
How wearing shoes to bed and headaches are associated without either being a cause of the other? It turns out that they are both caused by a common cause: drinking the night before. The total association observed can be made up of both confounding association and causal association. It could be the case that wearing shoes to bed does have some small causal effect on waking up with a headache. Then, the total association would not be solely confounding association nor solely causal association. It would be a mixture of both. (Neal 2020)
![]()

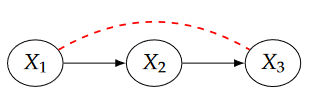
Causal Chain: In chain graphs, \(X_1\) and \(X_3\) are usually dependent simply because \(X_1\) causes changes in \(X_2\) which then causes changes in \(X_3\). \(X_2\) can be called the mechanism. (Neal 2020)
Controlling for \(X_2\) prevents information about \(X_1\) from getting to \(X_3\) or vice versa. (Pearl 2019) So, we cannot control for \(X_2\) when exploring the causal effect of \(X_1\) on \(X_3\).
![]()
Fork (Confounding Junction): Confounding bias occurs when a variable influences both who is selected for the treatment and the outcome of the experiment. In the figure, q is a confounder of X and Y. (Pearl 2019)
Q is a source of omitted variable bias. If we omit q in the regression of Y on X, it will not only pick up the association between X and Y, but also the association between X and Y that flows through q. Therefore, we should control for q when exploring the causal relationship between X and Y.
![]()

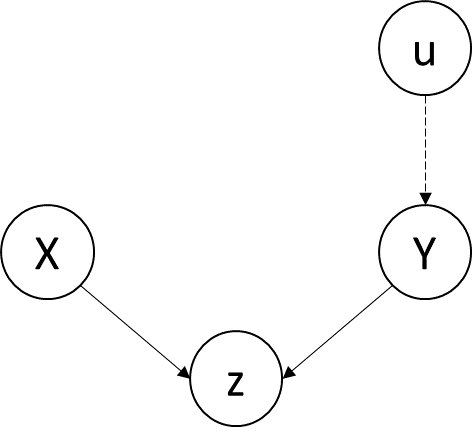
Collider (M-bias): In a collider graph, The variables X and Y start out independent, so that information about X tells you nothing about Y. But if you control for z, then information starts flowing through the “pipe”, due to the explain-away effect. (Pearl 2019) Therefore, we cannot control for z when exploring the causal relationship between X and Y.
![]()
Pros and Cons of RCT
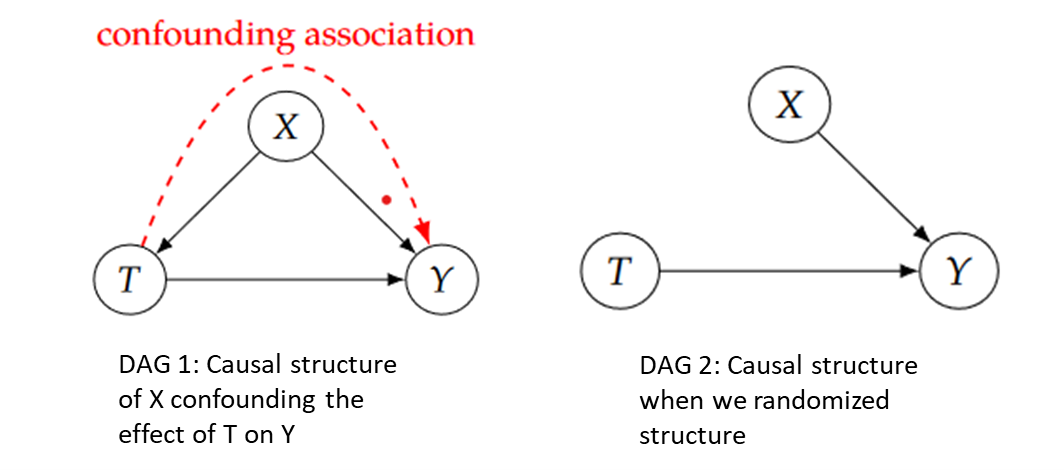
Pros: Association is causation. Randomized experiments guarantee that there is no confounding. As the Directed Acyclic Graph (DAG) shows, X is a confounder of the effect of T on Y. Non-causal association flows along the backdoor path T ← X → Y. However, if we randomize T, T no longer has any causal parents. This is because T is purely random. (Neal 2020)
![]()
Cons: RCTs may be expensive and time-consuming to implement. Randomization requires implementation of a carefully designed and closely monitored experiment - probably on a small scale (due to cost considerations) and or for a narrowly defined group (due to practical constraints) - which can limit the study’s external validity.
Quasi-experimental Method 2: Regression Discontinuity
Definition: For some programs, there is a clear eligibility threshold (cutoff): if you are below (above) that threshold, you qualify for the program and, if you are above (below) the threshold, you don’t. RD takes advantage of the cutoff. As long as the only thing that changes at the cutoff is that the person gets the treatment, then any jump up or down in the dependent variable at the cutoff will reflect the causal effect of treatment. (Bailey 2019)
![]()
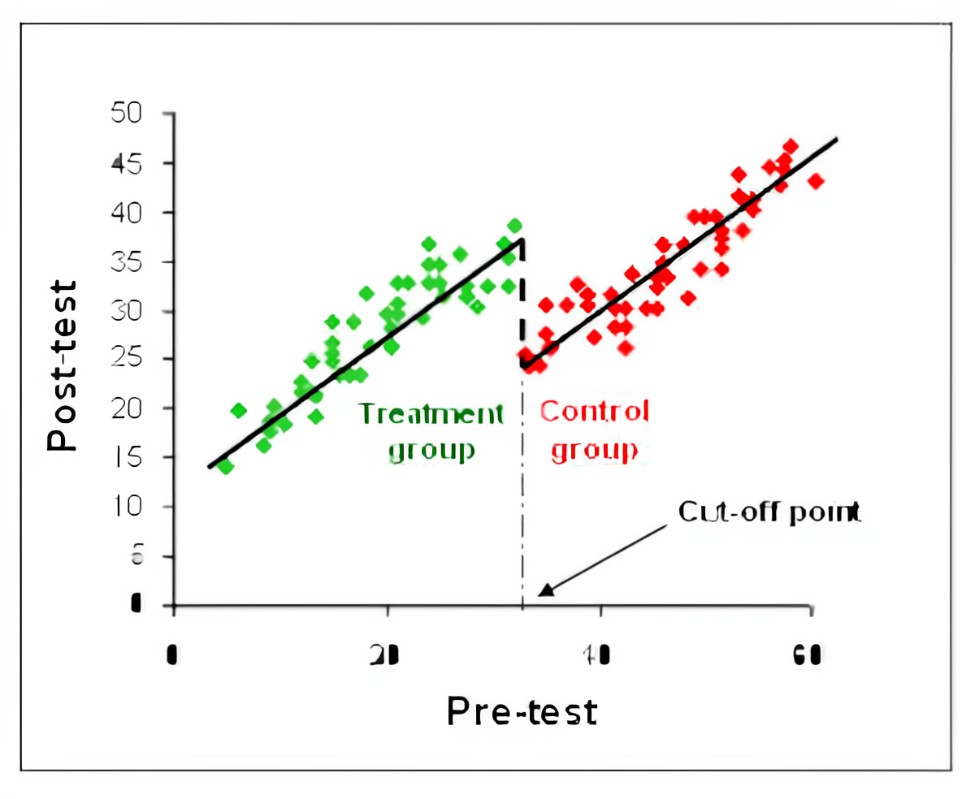
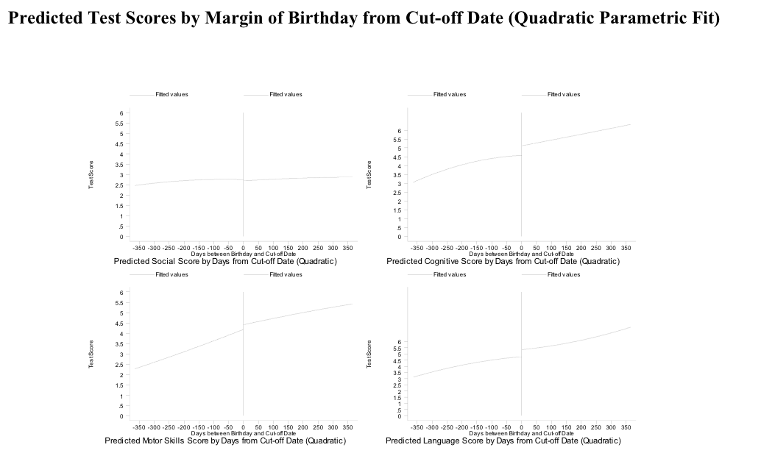
Example: (Gormley and Gayer 2005) The author explores the effect of Oklahoma’s universal pre-kindergarten (pre-K) program for four-year-olds on children’s test scores in Tulsa Public Schools. The author uses a regression-discontinuity approach that contrasts the performance in the test of children born just before the cut-off date (the treatment group) to the performance of children born just after the cut-off date (the control group), at the same time controlling for continuous age effects.
![]()
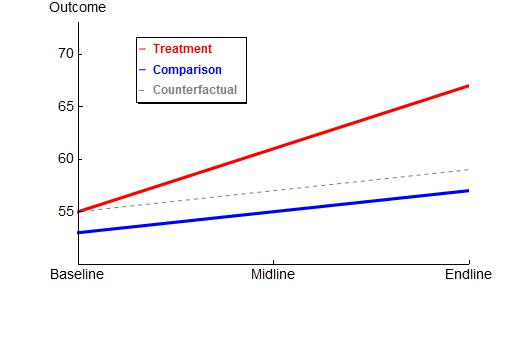
Example: (Eissa and Liebman 1996) This paper examines the impact of the Tax Reform Act of 1986 (TRA86) on the labor force participation and hours of work of single women with children. This paper uses all single women with children as the control group. The difference between the change in labor force participation of single women with children and the change of single women without children is the estimate of the effect of TRA886 on participation. This is essentially the difference-in-differences approach.
![]()
Quasi-experimental Method 5: Propensity Score Matching
Definition: Assume that we want to measure the effect of some policy “treatment,” but that people aren’t randomly assigned to this treatment. We could address selection bias by accounting for observed characteristics that are part of the “selection process” via stratification or multiple regression or use same set of variables to model the selection process explicitly, which is the approach taken by propensity score matching.
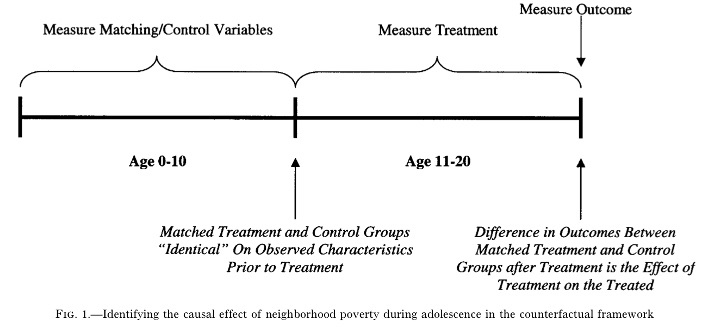
Example: (Harding 2003) This paper is trying to explore the effect of growing up in a high-poverty neighborhood on the probability of dropping out of high school or of experiencing a teenage pregnancy. Author uses propensity score to match each treated subject with one or more control subjects such that the treated subjects are, on average, identical to the control subjects on observable characteristics prior to treatment, and then compares individuals growing up in poor and nonpoor neighborhoods (treatment and comparison groups), who are otherwise identical on observable characteristics.
![]()